
本文总结了MySQL关系数据库在实际应用中的开发与设计经验。
1、 MySQL数据库为服务内部实现,严禁跨服务共享使用。
2、 各服务应使用独立的数据库资源,禁止直接共享数据表或访问凭证,确保服务间的数据隔离与安全。
3、 服务提供方可根据业务需求自主选择数据类型。
4、 服务A与B共用同一MySQL数据库,属典型反例。
5、 禁止将图片、文件等大容量数据存入MySQL数据库。
6、 设计表时需考虑删除策略,避免数据无限增长,确保数据管理的有效性和系统性能的持续优化。
7、 某服务因缺乏历史数据转储机制,长期积累形成千万级大表,成为典型反例。
8、 需重视MySQL数据库的一致性保障措施。
9、 从多个方面考量一致性的相关问题。
10、 确保大表与小表在拆分后的创建及删除操作中保持事务一致性。
11、 并发写入时需确保操作原子性,通过合法性检查控制修改,如限定数量,保障数据一致性。
12、 表字段冗余需确保数据类型相同,并在修改时保持同步更新。
13、 确保数据迁移前后表数量、记录数及校验值一致,保持数据完整性与准确性。
14、 主从库采用异步复制,无法保证数据强一致。
15、 设置缓存过期时间,使非热点数据自动失效,确保最终一致性;采用双淘汰策略,提升数据库与缓存的同步可靠性。
16、 微服务间存在共享依赖数据时,可通过优化流程或采用租约机制定期校验,以保障数据一致性,确保系统协同运作稳定可靠。
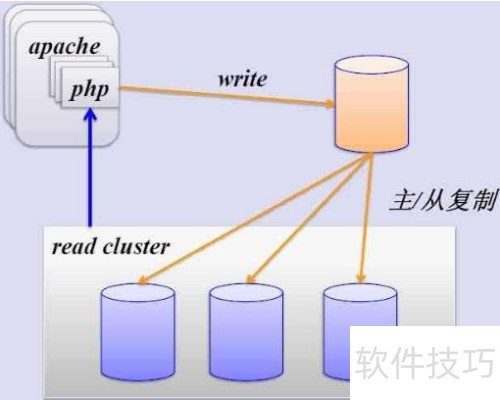
17、 合理规划MySQL数据库的规模与数量,确保系统高效稳定运行。
18、 单表数据建议控制在百万以内。
19、 单库表数量建议控制在百个以内。
20、 建议单表字段数控制在20至50个之间。
21、 服务组推出数据表完整性校验工具,确保信息一致准确。
22、 数据库异步复制可能导致短暂数据不一致。
23、 异地容灾发生故障需手动切换前,服务应提供数据完整性检查工具,用于辅助倒换决策,防止因数据问题导致切换后服务无法正常启动等严重后果。
24、 大规模存储需提前估算数据库容量。
25、 表数据容量预估
26、 单实例存储空间由表的总数、每张表最大存储的记录数(以万计)以及每条记录所占的KB数共同决定,三者相乘可估算出总数据空间,单位为GB。
27、 预留足够的空间用于存储binlog日志。
28、 备份所需预留空间等于保留天数乘以每日存储量。
29、 大规模存储需评估数据库性能以确保效率。
30、 依据服务的SLA指标(如吞吐量、响应延迟)进行测算,具体可参考以下数据标准。
31、 MySQL单实例批量插入吞吐量最低为每秒1000条。
32、 单个MySQL实例的并发读取吞吐量至少可达每秒1万次。
33、 Redis单实例每秒可支持5万到10万次并发读写操作。
34、 RedisCluster的并发读写吞吐量为每秒5万次,乘以实例数量。
35、 评估异地容灾所需网络带宽的数据复制量。
36、 估算方法:每秒变动记录数乘以每条记录字节数再乘以8。
37、 每秒持续上报1000条告警:1K乘以1K再乘8,等于每秒8兆比特。
38、 提前估算资源需求,明确服务器配置要求。
39、 服务器配置包括一个MySQL单实例节点和两个主从数据库节点,RedisCluster或Zookeeper通常需部署3个或5个节点以保证高可用性。
40、 MySQL 5.6单实例默认内存起始值为800M。
41、 MySQL支持多线程,可利用多核CPU;而单实例Redis采用单线程,最多占用一个CPU核心。
42、 磁盘需预估数据量、索引、复制日志及备份所占空间。
43、 网络带宽需按平均包大小乘以最大并发数计算,并预留带宽用于主从复制及异地容灾。
44、 建议合理拆分数据库实例与库,提升性能与管理效率。
45、 在分布式场景下,为节约资源与维护成本,同一产品内的服务可共享数据节点,同一服务组内的服务默认共用一个MySQL实例,以提升资源利用率和管理效率。
46、 根据数据重要性、表数量及单表记录规模,服务组内可细分至不同实例与数据库。
47、 当复制速度受限时,可通过单机多实例部署提升复制性能。
48、 单个IO性能受限,建议采用SSD提升速度。
49、 单实例存储通常为10G,每库含100张表,每表约100万条记录,60个字段,5个索引,每条记录大小约为2KB。
50、 严禁多个微服务共享同一数据库。

51、 大规模存储需重视书库结构的合理设计与优化。
52、 需重点关注以下几方面因素
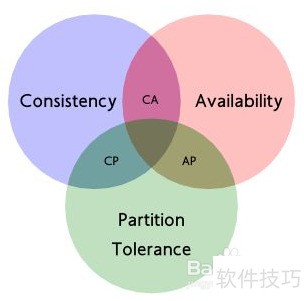
53、 明确业务模型类型,选择OLTP或OLAP,确定CAP中的两项,设计ER关系为一对多或多对多,并决定采用最终一致性还是强一致性。
54、 按业务关联性将表集中到同一数据库,减少跨库操作,提升性能与可靠性,降低实时处理成本。
55、 水平分区通过将单表按记录拆分到多个数据库或实例中,解决数据量过大导致的存储与性能问题,提升系统扩展性,关键在于合理选择拆分维度,但实施过程较为复杂,成本较高。
56、 定期将历史数据转储至文件或大数据系统,防止磁盘空间被占满。
57、 单表数据量宜控制在百万级别以内
58、 可采用读写分离策略,将访问频繁、吞吐量大的热点数据缓存至Redis,提升系统性能。


