
Python是当前最受欢迎、应用最广泛的编程语言,也是大数据时代必备的学习工具。其强大的数据分析库pandas尤为经典。接下来,我们将通过一个实例来展示Series结构中层次化索引的使用方法,帮助理解多级数据的处理方式。
1、 导入numpy、pandas库及Series、DataFrame类。
2、 创建一个具有层次索引的Series对象,命名为s1。
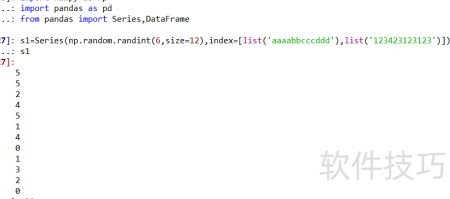
3、 通过s1.index可查看MultiIndex的层级索引结构。
4、 通过s1查询外层为‘c’的记录。
5、 通过s1查询外层为‘b’和‘c’的连续数据。
6、 如图

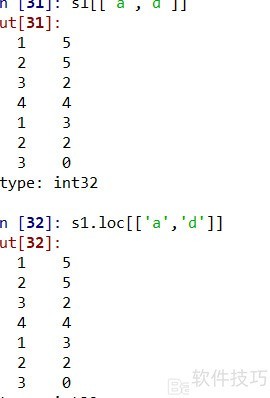
7、 当外层两个索引不连续时,可通过s1或s1.loc方法提取外层索引为a和d的数据,具体操作所示。
8、 要提取内层值为2的数据,直接调用s1即可实现。

9、 实现类似Excel数据透视表的多层次索引重构功能。
10、 s1.unstack(level=-1)表示将最内层索引转为列,s1.unstack(level=0)则是将最外层索引转为列;unstack的逆操作是stack,具体转换过程所示。




