
使用前先了解哈希表的概念与原理
1、 在了解HashMap前,需先理解Map的概念。数组通过下标访问元素,而Map则通过对象进行索引。用于索引的对象称为key,与之关联的对象称为value,二者构成键值对,实现基于特定键快速查找对应值的功能。
2、 HashMap通过哈希码实现元素的快速查找,其内部存储顺序不固定,无法保证元素的插入与输出顺序一致。

3、 从上述示例可以看出,Element作为键用于索引Figureout对象,即Element为键,Figureout为值。众所周知,Java中Object类的hashCode()方法默认基于对象内存地址生成哈希值,因此即使两个对象内容完全一致,只要它们是不同的实例,其hashCode()返回的结果也会不同。为了避免这一问题,在实际编程中需要重写hashCode()方法,使得内容相同的对象能够产生相同的哈希码。这样一来,当使用这些对象作为键进行存储或查找时,系统能正确识别它们的等价性,从而得到预期的运行结果,避免因哈希不一致导致的数据错乱或查找失败。
4、 根本原因在于Hashcode的差异使HashMap不同,但需始终遵循两大原则。
5、 只要hashCode方法能确保通过put()存入的数据可用get()正确获取,就不需要为每个不同对象生成唯一的哈希值。
6、 生成哈希码时应尽量让其数值分布均匀,避免大量哈希码集中在某一区间,以提升散列效果和数据存储效率。

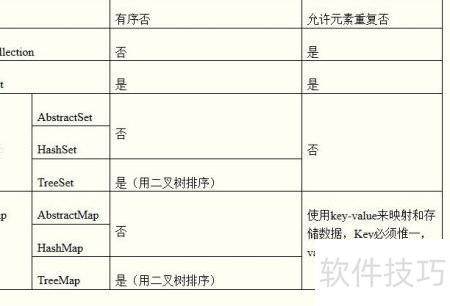
7、 HashMap允许键和值为null,而Hashtable不允许,具体差异可参考下表所示内容。
8、 Hashtable 是线程安全的集合类,而 HashMap 是其轻量级版本,但不具备线程安全性,适用于单线程环境,性能更优。

9、 HashMap在性能上优于Hashtable,尤其在非同步环境下效率更高。
10、 HashMap将Hashtable中的contains方法拆分为containsValue和containsKey两个方法,增强了功能的明确性。Hashtable的方法默认是同步的,适用于多线程环境,无需额外处理线程安全问题;而HashMap本身不同步,因此在多线程并发访问时,需由外部手动添加同步机制来保证线程安全。两者在性能和使用场景上存在差异:HashMap因非同步特性,在单线程环境下效率更高、更灵活;Hashtable则因内置同步机制,在多线程操作中更为稳妥,但性能相对较低。此外,两者还有其他多方面对比,具体可参考相关对照图表。



