对计算机专业的学生而言,哈希算法在大学数据结构课程中曾有所接触,但随着时间推移,多数人逐渐淡忘了相关内容。工作后由于实际应用较少,也未能深入研究。直到某天在项目开发中,发现有人同时重写了hashCode和equals方法,才引发思考:hashCode到底是什么?为何这两个方法需要一起重写?这一疑问促使重新审视哈希机制的原理与作用。原来,hashCode在对象存储与查找中起着关键作用,尤其在集合类如HashMap中影响性能与正确性,是Java等语言中不可忽视的重要概念。
1、 首先查看JDK 1.8源码中Object类的hashCode方法,该方法被声明为native,意味着其具体实现由底层非Java语言编写。其核心原理是基于对象在内存中的物理地址(即内部地址)计算出一个整型哈希值。从JDK源码的注释可以看出,该值的生成直接关联对象的内存位置。需要注意的是,这是Object类默认提供的本地实现,与后续在自定义类中重写(override)的hashCode方法完全不同,二者不应混淆。此机制为Java对象提供了一种基础的、默认的散列支持,广泛应用于集合框架中。
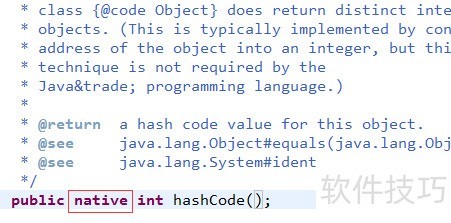
2、 查看JDK源码中关于hashCode的注释,用我蹩脚的英文大致翻译如下。
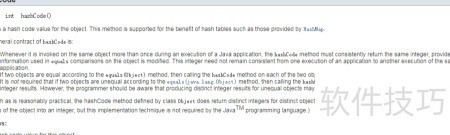
3、 hashCode方法用于生成对象的哈希值,主要为支持哈希表的数据结构提供服务。该哈希值在HashMap等集合中被广泛使用,以提高数据存储和查找的效率,是实现快速定位和优化性能的重要基础。
4、 在程序运行期间,若某个对象用于equals方法比较的数据未发生变化,则该对象的hashCode方法无论被调用多少次,都应返回相同的整数值。需要注意的是,一旦参与equals比较的属性被修改,hashCode的结果可能随之改变;但不同运行周期之间,同一对象的哈希值无需保持一致。如果通过equals(Object)方法判定两个对象相等,那么它们的hashCode值必须相同,这是保证哈希结构正确性的基础。反之,若两个对象不相等,其hashCode值虽然可以不同,但也允许相同,即不同的对象可拥有相同的哈希码。尽管如此,开发者应当意识到,尽量为不同的对象生成不同的哈希值,有助于减少哈希冲突,提升哈希表的存取效率。良好的哈希函数设计应兼顾分布均匀与计算高效,从而优化整体性能。因此,在重写hashCode方法时,需确保与equals逻辑协调一致,并综合考虑参与比较的字段,以实现稳定且高效的哈希行为。这一约定虽不强制跨程序运行保持一致性,但在单次运行中必须严格遵守,以保障集合类如HashMap、HashSet的正常运作。
5、 尽管如此,Object类中定义的hashCode方法对不同对象通常返回不同的哈希值。该方法并非用Java语言实现,而是一个本地方法,其底层机制是将对象的内存地址转换为整数形式的哈希码,因此在默认情况下,不同对象的地址不同,所生成的哈希值也互不相同。
6、 重写equals方法时必须同时重写hashCode,是因为Java规范中明确规定:两个对象若通过equals判断相等,则它们的hashCode必须相同。这是为了确保对象在基于哈希的集合(如HashMap、HashSet)中能正确存储和查找。若不遵守此约定,可能导致相等的对象被当作不同元素处理,破坏集合的正常功能。因此重写时应结合业务逻辑,保证一致性与稳定性。
7、 HashMap是一种基于哈希表实现的键值对存储结构,其底层在JDK1.6中采用数组加链表的方式组织数据。从JDK1.8开始,为了提升性能,在链表长度达到8时会自动转换为红黑树,当长度减少至6以下时又退化为链表,这样设计的目的是在数据量较大时提高查找、插入和删除的效率。在存储元素时,HashMap首先通过对象的hashCode方法计算出对应的数组索引位置,若该位置已有元素存在,则形成链表或红黑树来处理哈希冲突。获取元素时同样先利用hashCode定位到数组中的具体位置,再通过equals方法遍历链表或树结构逐一比对,找到匹配的键值对。因此,合理地重写hashCode和equals方法对于保证HashMap的正确性和性能至关重要。整个过程体现了哈希机制与数据结构优化的结合,使得HashMap在大多数场景下都能保持较高的操作效率。

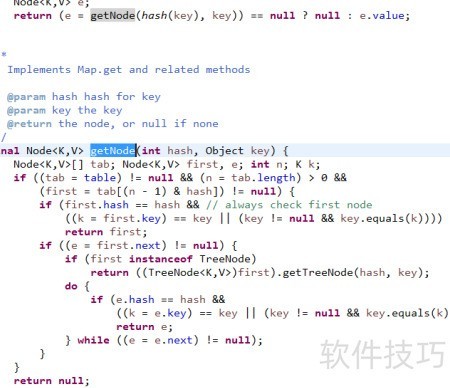
8、 在HashMap的get方法中,首先根据传入的哈希值计算出数组对应的索引位置,并将该位置链表的第一个节点赋给变量first。接着判断:若first节点的哈希值与目标对象的哈希值一致,且其键(key)与传入键为同一引用或通过equals方法比较结果相等,则说明找到了目标节点,直接返回其值。若首个节点不符合条件,则表明目标可能位于后续节点中。此时程序会沿着链表依次遍历每一个后续节点,持续进行哈希值和键的比对,直到找到完全匹配的节点为止,最终返回对应值;若遍历结束仍未找到,则返回null。整个查找过程兼顾了效率与准确性。
9、 在HashMap的put方法中,通过hash值确定索引位置,若该位置无链表,则创建新节点,并将数据存入其中。
10、 若索引位置已有节点,先判断链表首个节点是否为待存数据的节点,若是,则表明该键已存在,将触发后续覆盖操作,即更新对应的值。
11、 若首个节点不符合条件,首先判断其是否为树节点类型。若是,则采用红黑树的查找算法进行定位;若不是,则对链表进行遍历,检查目标节点是否存在。若存在,则更新其值;若不存在,则在链表末尾创建新节点,并将待存信息写入其中。

12、 在Java开发中,虽然我已经积累了两年多的经验,但实际直接使用hashCode的场景并不多见。它主要应用于底层数据结构的实现中,尤其在需要高效查找的场合。hashCode的核心作用在于提升查找效率。具体来说,它通过计算对象的哈希值,确定该对象在数组中的存储位置,也就是索引下标。这样一来,原本可能需要遍历整个链表才能找到目标元素的情况,就变成了先通过哈希值快速定位到特定桶(数组位置),大大缩小了搜索范围。如果所有元素都挤在同一条链表上,查找就必须逐个比对,效率极低。正是为了避免这种问题,哈希表才采用数组与链表结合的结构。hashCode负责快速定位到对应的链表,而真正确认元素是否匹配,则依赖equals方法。程序会遍历对应链表中的每个节点,通过equals比较键(key)是否相等,一旦匹配成功,便能取出对应的值(value)。因此,hashCode和equals共同协作,实现了高效的存取操作。
13、 哈希算法在实际中应用广泛,例如数据库分表场景。当单张数据表记录过多、超出承载能力时,可采用分表策略,其中最简便的方法是哈希分表。假设需将数据分散到5张表中,可对表的ID进行除以5取余操作,根据余数决定该记录存入哪一张表。这种方式不仅有效解决了单表容量瓶颈,还能使数据较为均匀地分布在各个表中,提升系统性能。但在后续查询时,必须先对ID进行相同的取余运算,才能准确判断目标数据所在的表,从而定位并获取信息。这种方法简单高效,适用于大规模数据管理。
14、 接下来举个小例子

15、 猜到结局了吗