
ABBYY FineReader Engine是一款功能强大的软件开发工具包,专为构建高效的应用程序而设计,可处理图像、PDF及扫描文档的打开、内容识别与解析。它能精准提取文本信息,并支持多种格式的导出,如纯文本PDF、Microsoft Office文档以及XML等。其中,XML格式特别适用于将OCR识别结果无缝集成到其他系统中,实现数据的高效共享与利用,满足多样化的业务需求。
1、 选择任务,查看操作说明,参考源码示例或运行程序文件。
2、 安装FineReader需遵循开发机上的多个步骤。
3、 首先需安装授权服务器。若仅一名开发人员使用SDK,可直接将其安装在开发用计算机上;若多名开发人员需从不同工作站调用FineReader功能,则应将授权服务器部署在所有开发人员均可访问的共享应用程序服务器上。请注意,授权服务器必须安装于物理设备,不可运行在虚拟机环境内,尽管相关技术本身支持在虚拟机及云平台中使用。通过配套的授权管理工具,用户可方便地添加并激活所持有的许可证,无论该许可证为试用版本或正式购买版本,均可完成配置与启用操作,确保开发工作顺利进行。
4、 将FineReader Engine安装至开发机,并与授权服务器建立连接即可完成配置。
5、 安装完成后,若使用的是Visual Studio 2010或2012版本,还需执行若干额外步骤,方可正常使用可视化组件(控件)。具体操作流程可参考随产品附带的SDK帮助文档中的在不同版本的Visual Studio中使用可视化组件页面,其中详细说明了配置方法和注意事项,确保组件正确集成与运行。
6、 现在可使用SDK进行开发,参考前文代码库中的示例应用,或直接开始构建自己的程序。
7、 首先创建一个Windows窗体应用程序,可使用C或Visual Basic语言。本文示例基于Visual Studio 2010进行开发,适用于常见的桌面程序设计场景。
8、 接着把ABBYY控件加入Visual Studio的工具箱,在其中新建了一个名为ABBYY的独立区域,便于后续调用和管理相关组件,提升开发效率与界面整洁度。
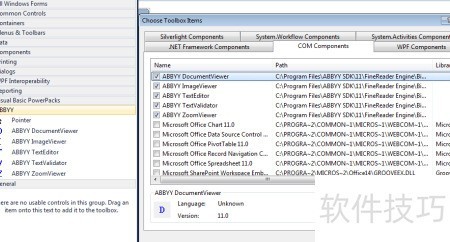
9、 在安装过程中,已将该项目的引用添加至ABBYY Inc.Net Interops文件夹中的三个Interop DLL文件,并完成注册,同时将这三个文件一并加入全局程序集缓存(GAC)中。
10、 以下介绍Windows窗体设计视图中包含的五个ABBYY控件。
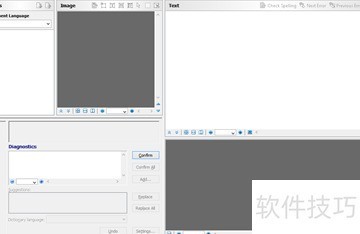
11、 始于左上,顺时针方向依次排列如下:
12、 文件浏览器用于展示已加载图像或文件的页面列表,呈现各页面处理进度,支持缩略图与详细信息两种查看模式。
13、 图像浏览器允许用户查看和编辑文件浏览器中选定的页面内容。
14、 文本编辑器允许用户查看并修改FREngine在指定页面上识别出的文字内容,便于精确调整和校对文本信息。
15、 动态浏览器支持用户放大或缩小图像浏览区域,便于查看细节或整体画面。
16、 文本校验器允许用户修正扫描识别中未能正确读取的文本部分,同时提供拼写检查功能,作为文件校对的交互界面。
17、 通过将各控件添加到代码中的ComponentSynchronizer对象,即可轻松实现文件与页面的同步,操作简便高效。
18、 以下通过一个简单示例,展示如何利用五个FineReader控件打开窗体并加载PDF文件。
19、 {
20、 }
21、 {
22、 }
23、 {
24、 {
25、 }
26、 }
27、 {
28、 }
29、 {
30、 }
31、 在实际应用中,通常会设置一个按钮,供用户点击后从文件系统选择需打开的文件。务必记得及时卸载引擎,否则将占用工作站授权,直至在授权服务器上手动释放。进行COM交互时,必须重视资源与内存管理,避免因资源未释放导致系统负担加重或授权浪费,确保程序运行稳定高效。
32、 对已加载文件进行识别处理较为简便,以下是管理该流程的具体方法。
33、 {
34、 }
35、 progressHandler 可使界面持续响应,便于用户在长时间文档识别过程中随时发起取消操作,及时终止任务。
36、 该软件默认识别英文,若需识别其他语言或多种语言混合的文档,可在打开文件前调整RecognizerParams中的SetPredefinedTextLanguage设置,具体操作步骤如下:进入参数配置界面,选择所需语言或语言组合,保存设置后即可实现对应语言的准确识别。
37、 调用文档对象的Export()方法可导出加载文件,如下代码所示,能将文件内容保存为RTF格式。
38、 ABBYY FineReader Engine 支持多种配置文件,可根据具体应用场景自动优化处理流程。通过配置文件,程序能自行启动并智能设定最佳的OCR处理参数,以确保识别质量。当前系统提供了多个预设配置,适用于不同类型的文档识别需求,提升处理效率与准确性。
39、 文档转换准确率——提升文档转为可编辑格式时的精确性与可靠性,确保内容完整无误。
40、 文档转换速度优化,提升文档转为可编辑格式的处理效率。
41、 提升电子档案创建过程中的准确率,确保信息完整无误。
42、 优化电子档案创建过程中的文档归档速度,提升整体效率。
43、 优化电子图书馆构建过程中的精准度,提升图书归档的准确性与可靠性。
44、 优化电子图书馆建设过程中的书籍归档速度,提升整体效率。
45、 提升从文件中提取文字的准确度,确保内容识别更加精确可靠。
46、 提升从文档中提取文字的速度,优化处理效率。
47、 识别图像中短小文本片段的技术,精准定位并提取关键文字信息。
48、 条形码识别功能,用于快速提取条形码信息。
49、 商务卡处理——自动识别和提取名片信息。
50、 仅将文件转换为高压缩无损图片并保存为PDF格式,确保内容完整且体积更小。
51、 可通过调用Engine.LoadPredefinedProfile加载预设配置文件,同时支持以.ini格式创建用户自定义配置。用户可根据软件内置帮助文档中的详细指引,自行编写符合需求的配置文件。完成自定义后,使用Engine.LoadProfile方法即可载入并应用这些个性化设置,实现灵活的功能配置与管理,提升使用效率与操作便捷性。
52、 本文所涉及的技术基于FineReader Engine的Windows SDK,但ABBYY还提供多种其他解决方案。该引擎不仅适用于Windows系统,还支持Mac OS、Linux以及各类移动平台的SDK开发,满足跨平台应用需求。其旗下的FlexiCapture Engine SDK具备强大的数据采集能力,适用于复杂文档信息的自动化提取。此外,ABBYY将服务扩展至云端,通过部署在Azure上的云环境,为开发者提供便捷的Web API接口,便于集成与调用。对于无需深度开发的用户,ABBYY也推出了多款功能完善、开箱即用的OCR识别工具和数据采集产品,覆盖不同行业应用场景,帮助用户高效完成文本识别与结构化数据提取任务,提升整体处理效率。
53、 ABBYY FineReader Engine 软件开发工具包操作简便,易于配置,帮助您轻松打造具备高效光学字符识别功能的应用程序,显著提升文档处理能力与工作效率。


