
利用样本估计总体通常依据正态分布,即Z分布的性质。尽管当样本量小于30时需对结果进行修正,但实际中多数情况样本量超过30,因此我们优先讲解在正态分布前提下,如何用样本均值来估计总体均值。至于不符合正态分布的小样本数据,将在后续卡方检验部分详细说明其处理方法。
1、 样本均值作为总体均值的点估计。
2、 所谓样本估计总体,是指利用样本数据中的统计量(如均值、标准差等)来推断整个总体的相应参数。在之前的内容中曾提到样本分布与总体分布之间的关系,其中一个重要结论是:样本均值的期望等于总体均值。基于这一性质,若我们有足够把握认为所抽取的样本具有代表性,能够反映整体情况,便可采用样本均值作为总体均值的估计值,这就是最直接的一种参数估计方法。虽然在现实中仅凭一个样本就完全代表总体往往难以实现,但随着样本容量的增加,样本均值趋于稳定,并逐渐接近真实总体均值。因此,在实际应用中,当样本量足够大时,通常可以将样本均值视为对总体均值的良好估计。例如,若随机抽取1000名北京市10岁儿童的身高数据,计算得平均身高为1.30米,则可据此推断,北京市该年龄段儿童的平均身高大致也为1.30米。这种方法在统计推断中具有广泛的应用价值。
3、 范围估算
4、 通常情况下,点估计并不准确。例如,若仅抽取100名学生,测得平均身高为1.30米,就断定北京市所有10岁儿童的平均身高为1.30米,显然是不合理的。为此,可采用区间估计的方法。在深入探讨之前,需先理解几个相关的基本概念。
5、 所示为样本均值的分布情况,中间刻度表示多个样本均值的平均值,即抽样分布的均值。左右第一个刻度分别代表均值加减一个标准差,第二个刻度为均值加减1.96倍标准差,第三个为3个标准差。这些区间对应的覆盖面积分别为68%、95%和99.7%,该面积反映的是概率。例如,身高在1.30上下一个标准差范围内的人群约占总体的68%,两个标准差内约占95%,三个标准差内则接近99.7%。这说明大多数样本均值集中在分布中心附近,离均值越远,出现的概率越低。
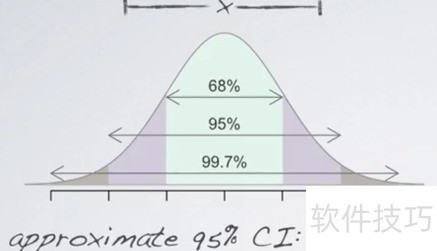
6、 其次,当样本数量足够大时,样本均值会趋近于总体均值。然而目前仅抽取了一个样本,因此我们需借助该单一样本的分布来推断多个样本均值的分布情况,因为多组样本均值的平均值即等于总体均值。参考上图及前述示例,已知均值为1.30,但标准差尚不明确。
7、 第三,样本均值分布的标准差等于总体标准差除以样本量的平方根。若已知总体标准差为0.1,则可计算出样本均值分布的标准差为0.01(即0.1除以根号10)。由此可知,该样本均值分布的均值为1.30,标准差为0.01,分布特征已明确,便于后续统计推断与分析。
8、 第四,根据上述图表,从左至右依次为:1.27(即1.30减去0.03)、1.2804(1.30减去0.0196)、1.29(1.30减去0.01)、1.30、1.31(1.30加上0.01)、1.3196(1.30加上0.0196)、1.33(1.30加上0.03)。由此可以得出以下结论:我们有68%的把握认为北京市10岁儿童的平均身高落在1.29米到1.31米之间;有95%的信心判断其身高在1.2804米至1.3196米范围内;更有高达99.7%的概率确信该群体身高处于1.27米到1.33米的区间内。可以看出,置信区间越宽,我们的判断就越稳妥,结论的可靠性也越高。这种统计方式有助于更科学地评估总体特征的可能范围。


