java.util包包含重要集合类,学习集合类时,重点掌握其内部结构与遍历集合时使用的迭代模式。
1、 集合类特性:常用类的区别对比
2、 ArrayList:单个元素存储,查询效率高。
3、 Vector:单个元素存储,线程安全,适合查询场景。
4、 LinkedList:单个元素存储,更适合插入和删除操作。
5、 HashMap:键值对存储,允许元素为空。
6、 Hashtable:键值对存储,线程安全,不允许元素为空。
7、 WeakHashMap是一种特殊的HashMap,它对键使用弱引用。当键不再有外部引用时,键可被垃圾回收机制回收。
8、 什么是迭代器
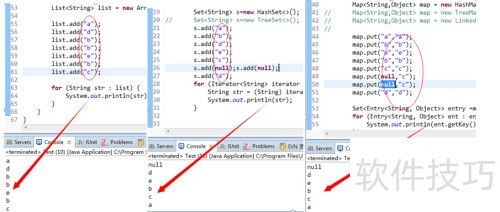
9、 某些集合类支持通过 java.util.Iterator 接口进行内容遍历,用于逐一访问集合中的元素。Iterator 可以对集合对象的每个元素依次操作。获取 Iterator 时,会包含集合的一个快照状态。通常,在遍历 Iterator 过程中,不建议直接修改底层集合,以免引发意外行为。
10、 Iterator和ListIterator的区别是什么?
11、 Iterator可用于遍历Set和List集合,而ListIterator仅能用于遍历List集合。
12、 Iterator仅支持正向遍历集合,适合用于获取和移除元素。而ListIterator继承了Iterator,能够实现列表的双向遍历,同时提供修改元素的功能,例如添加或替换元素,以及获取前后元素的索引等操作。
13、 Collection是接口,表示集合;Collections是工具类,提供集合操作方法。
14、 Collection是集合类的顶级接口,其主要子接口有Set和List。
15、 Collections是集合类的工具类,提供静态方法用于集合的搜索、排序和线程安全化等操作。
16、 List有序可重复,Map键值对应唯一,Set无序不重复。
17、 列表按特定顺序存储元素,支持元素重复。
18、 Set 不允许重复元素,内部自动排序,无固定顺序。
19、 Map用于存储键值对,支持一个键对应多个值。
20、 HashMap与Hashtable的区别在于线程安全、速度及Null值处理的不同。
21、 都属于Map接口,实现将唯一键映射到特定值的功能。
22、 历史渊源深厚
23、 Hashtable基于古老的Dictionary类,HashMap是Java 1.2新增的Map接口实现。
24、 二.一致性:
25、 Hashtable支持线程同步,是线程安全的;而HashMap不支持线程同步,是非线程安全的。
26、 值得拥有
27、 HashMap 无序且不排序,允许一个 null 键和多个 null 值。
28、 Hashtable 与 HashMap 类似,但不支持 null 键和 null 值。
29、 工作效率需提高。
30、 Hashtable比HashMap慢,因为它进行了同步处理。
31、 如何实现HashMap的同步
32、 通过 Map m = Collections.synchronizedMap(hashMap),可让 HashMap 实现线程同步,从而安全地在多线程环境中使用。
33、 ArrayList与Vector的区别在于线程安全、性能及使用场景的不同。
34、 ArrayList和Vector的区别主要体现在两个方面。
35、 步调一致协调性
36、 Vector是线程安全且同步的,而ArrayList线程不安全,不同步。
37、 二、动手操作:
38、 Vector支持多线程操作,但性能不及ArrayList。
39、 数据持续增长:
40、 ArrayList 和 Vector 都有初始容量,当存储元素超出容量时,需要扩充存储空间。扩容时并非仅增加一个单元,而是增加多个存储单元,以满足更多数据的存储需求,这种方式可以减少频繁扩容带来的性能开销。
41、 Vector容量默认翻倍,ArrayList容量默认增加一半。
42、 Vector允许我们自行设置增长大小,而ArrayList未提供相关方法。
43、 LinkedList 和 ArrayList 的区别是什么?
44、 两者均实现了List接口,区别在于:
45、 ArrayList基于动态数组,LinkedList基于链表结构,两者数据结构实现方式不同。
46、 访问List中的任意元素时,ArrayList的效率高于LinkedList。因为LinkedList的get方法需要从一端开始依次查找,直到目标位置,而ArrayList可直接通过索引定位元素,无需遍历。
47、 LinkedList在增删操作上优于ArrayList,因为ArrayList需要移动元素以维护连续内存。
48、 附加:
49、 LinkedList实现了List接口,支持null元素。它还提供了在链表头部或尾部进行获取、删除和插入的操作方法,这些功能使得LinkedList可以作为栈(stack)、队列(queue)或双向队列(deque)使用。
50、 请注意,LinkedList不具备同步方法。当多个线程同时访问某个List时,需要自行实现访问同步。一种解决办法是在创建List时,生成一个同步的List对象:
51、 数组与动态数组有何不同?
52、 以下是Array与ArrayList的区别:
53、 Array可容纳基本类型与对象类型,而ArrayList仅能存储对象类型。
54、 Array大小固定,ArrayList容量可变,能够自动调整。
55、 ArrayList拥有更多方法与特性,例如addAll()、removeAll()、iterator()等,功能更为丰富。
56、 集合对基本类型数据采用自动装箱,以减少编码工作量。不过,处理固定大小的基本类型时,这种方式较慢。
57、 枚举接口与迭代器接口有何不同?请简要说明两者之间的主要区别。
58、 Enumeration的速度为Iterator的两倍,且内存占用更低。然而,Iterator在安全性上远胜Enumeration,因为它能防止其他线程修改正在被迭代的集合内容。此外,Iterator支持调用者删除底层集合中的元素,而这是Enumeration无法实现的功能。
59、 HashSet与TreeSet的区别有哪些?
60、 HashSet具有以下特征:不重复、无序性。
61、 A. 无序(无法确保元素排列顺序,顺序可能改变)B. 不同步C. 支持空值(集合元素可为 null,可添加多个 null,但会自动覆盖)。
62、 将一个元素存入HashSet时,HashSet会调用该对象的`hashCode()`方法以获取其哈希值,并依据此哈希值决定对象的存储位置。简而言之,HashSet判断两个元素是否相等的标准是:两者的`equals`方法返回`true`,且它们的`hashCode()`方法返回值相同。
63、 需要注意的是,如果要将某个对象放入HashSet中,那么在重写该对象所属类的`equals`方法时,也应该同时重写`hashCode()`方法。规则为:若两个对象通过`equals`方法比较结果为`true`,则它们的`hashCode`值必须相同。此外,用于定义`equals`方法比较逻辑的属性,都应当参与`hashCode`值的计算过程。
64、 这样可以确保对象在HashSet中的正确存储与快速检索,避免因哈希值不一致或比较逻辑冲突导致的问题。这是保证HashSet功能正常运行的重要基础。
65、 TreeSet具有以下特性:
66、 一切井然有序
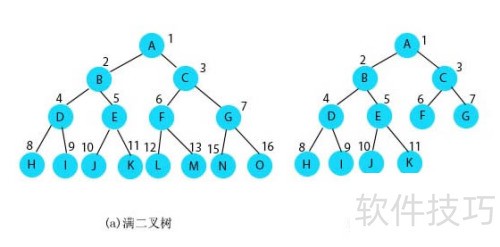
67、 TreeSet基于树形结构实现(二叉树),内部元素有序排列,支持高效排序操作。
68、 TreeSet是SortedSet接口的唯一实现类,能够保证集合元素有序。它支持两种排序方式:自然排序和定制排序。自然排序是默认方式,元素会按其自然顺序排列;定制排序则需要集合中的对象实现Comparable接口,从而定义自己的排序规则。这种方式提供了更大的灵活性以满足不同需求。
69、 TreeSet与HashSet类均无get()方法获取元素,只能借助迭代器进行访问。
70、 树形结构:
71、 B. 禁止出现空值
72、 HashSet基于HashMap实现,TreeSet基于TreeMap实现,只是Set仅使用了Map的键部分。
73、 Map的键与Set集合均具有唯一性特性,而TreeMap除此之外还具备有序性特点。
74、 TreeSet 类与 HashSet 类均无 get() 方法获取元素,只能借助迭代器进行访问。
75、 HashSet基于哈希算法实现,性能高于TreeSet,一般优先选用HashSet。只有当需要对元素进行排序时,才使用TreeSet来满足排序需求。
76、 HashMap、LinkedHashMap和TreeMap的区别在于存储顺序、排序方式及性能特点。
77、 HashMap、LinkedHashMap 和 TreeMap 均为 Map 接口的实现类,各自具有不同的特性与用途。
78、 LinkedHashMap继承于HashMap,是其子类。
79、 Map 用于存储键值对,通过键获取值。键必须唯一,值可重复。
80、 HashMap 的底层基于数组实现,采用线性顺序存储,同时通过单链表解决哈希冲突。Key 的 hashCode 经过二次哈希后,取模数组长度得到索引值。支持 key 为 null,会存放在索引 0 的位置。由于基于数组结构,引入了负载因子(loadFactor)和临界阈值(threshold)的概念,当元素数量超过阈值时会触发扩容(resize)。扩容操作较为耗时,且在冲突情况下需要通过链表遍历查找,因此选择合适的初始容量非常重要。HashMap 在存取数据时性能较高。在迭代过程中,一维结构使用数组,而二维结构则依赖链表实现访问。
81、 HashMap 是一种常用的 Map 实现,它通过键的 HashCode 值存储和获取数据,能够以键为索引快速定位对应的值,从而实现高效的访问性能。在 HashMap 中,最多只允许一个键为 Null 的记录,但可以存在多个值为 Null 的记录。此外,HashMap 不具备线程同步功能,这意味着多个线程同时对 HashMap 进行写操作时,可能会引发数据不一致的问题。如果需要在多线程环境下使用 HashMap,可以通过 Collections 类提供的 synchronizedMap 方法为其添加同步支持,从而保证线程安全。
82、 2. LinkedHashMap 是 HashMap 的子类,其内部结构由数组和双向链表共同组成。数组用于存储数据的线性顺序,而每个元素还通过单向链表连接,同时维护了一个额外的双向循环链表以保证特定顺序。默认情况下,`access-order=false` 表示按照插入顺序存储和访问;如果设置为 `access-order=true`,则会按照访问顺序进行排列(即最近访问的元素排在最后)。此外,`removeEldestEntry=false` 是默认值,但若设为 `true`,则可以实现一个基于 LRU(最近最少使用)算法的缓存容器。此时需要指定淘汰策略及容量上限,其中 `access-order=true` 对应最近使用的顺序,而 `access-order=false` 则对应最新插入的顺序。相较于 HashMap,LinkedHashMap 的存取性能略低,但差异不大。其内部维护了头节点 `header`,其中 `header.after` 指向尾部方向,`header.before` 指向头部方向。在迭代遍历时,`entrySet().iterator()` 的行为与 HashMap 类似(这里可能有些令人困惑,因为默认并未按线性顺序迭代,若要调整需重写 `entrySet()`、`keySet()` 和 `values()` 方法)。因此,当需要设计缓存功能时,LinkedHashMap 是一个不错的选择,通常需要继承并自定义相关逻辑。
83、 3. TreeMap 的内部结构是一棵红黑树,这是一种特殊的二叉搜索树,能够确保数据有序存储。TreeMap 支持通过 Comparator 接口指定比较规则,或者要求 key 实现 Comparable 接口以便自动排序。需要注意的是,TreeMap 的 key 不允许为 null,否则会抛出异常。由于红黑树的特性,在插入或删除节点时需要对树结构进行调整,因此相比 HashMap 或 LinkedHashMap,TreeMap 的存取性能稍逊一些。然而,它的查找操作基于有序比较,性能中规中矩。在迭代遍历时,TreeMap 使用红黑树的中序遍历方式,返回的结果是一个有序序列。因此,当应用程序需要对键值对进行排序时,TreeMap 是一种理想的实现方式。














