K-中心点算法与K-means原理相似,区别在于前者不采用类别样本的均值作为中心,而是在类内选择一个到其他所有样本距离总和最小的实际样本点作为中心。
1、 加载数据集
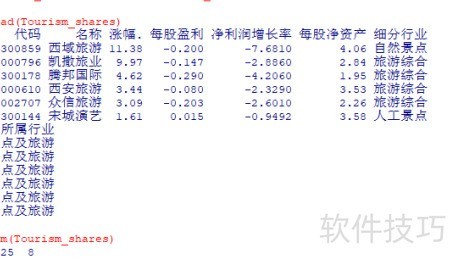
2、 开展聚类分析。
3、 加载cluster软件包以进行聚类分析。
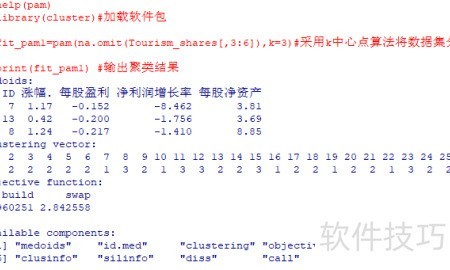
4、 使用k中心点算法对剔除缺失值后的 Tourism_shares 数据集进行聚类,设定聚类数量为3,得到分类结果 fit_pam1。
5、 输出聚类分析结果,展示fit_pam1的分类情况。
6、 结果中的Medoids表示各类别中心点对应的具体样本序号。
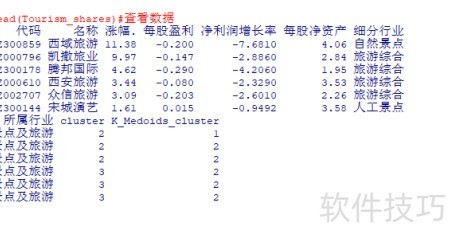
7、 记录各样本的分类归属。
8、 查看旅游份额数据的前几行内容。
9、 与K-means聚类结果相比,可见不同样本点在两种算法下的分类存在差异。
10、 画散点图。