近期开展接口测试时,针对report接口需将数据导出为PDF并读取其中内容,实际操作中遇到了若干问题,现将相关情况整理汇总如下。
1、 Java中可通过iText库解析HTTP响应并生成PDF文件。
2、 首先选择IText工具,导入所需jar包,具体使用版本所示。

3、 将HTTP响应数据转为PDF的过程颇为曲折,耗费大量时间查阅资料,正因如此,我才想把这段经历记录下来,以供日后参考。
4、 少废话,先讲遇到的坑
5、 区分字符流与字节流
6、 此处可自行搜索了解,简单来说就是:
7、 Java 提供了专门用于输入输出操作的 java.io 包,其中包含 InputStream、OutputStream、Reader 和 Writer 四个核心类。InputStream 和 OutputStream 是面向字节流的抽象类,适用于处理字节数据或二进制文件,片、音频等。而 Reader 和 Writer 则是为字符流设计的,每个字符占用两个字节,主要用于读写文本数据,能更好地支持字符编码转换。这两组类分别针对不同类型的數據处理需求,提供了丰富的实现类和功能方法,是 Java 实现文件读写、网络通信等 I/O 操作的基础。
8、 因此,处理PDF需采用字节流方式
9、 依据响应生成相应PDF文件
10、 当连接的内容类型为application/pdf时,表示将数据导出为PDF格式文件。
11、 数据流处理
12、 //
13、 咨询开发后优化了代码,现将修改后的代码分享如下
14、 利用ByteArrayOutputStream结合iText实现PDF文档的生成与处理功能。
15、 }
16、 }
17、 读取PDF文件内容
18、 网上搜集而来,两种方法均可行,代码如下所示。
19、 输出编号及对应页的文本内容,格式为编号:页码 文本,通过读取指定PDF文档的每一页提取其中的文字信息并进行显示。
20、 }
21、 }
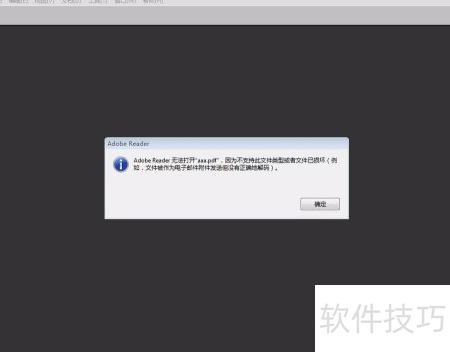
22、 URL传递中文参数时出现乱码,导致生成的PDF内容异常。问题已解决,需对参数进行百分号编码与解码处理,确保字符正确传输与显示。
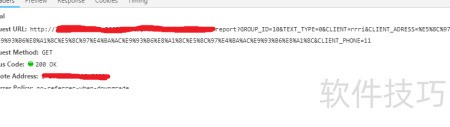
23、 读取PDF时按行提取文本会导致原始格式丢失,尤其是表格数据难以准确还原,所示,该问题目前仍未得到有效解决。

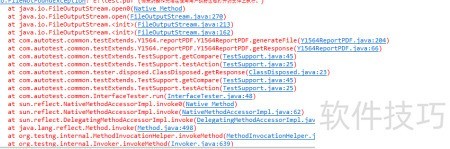
24、 测试用例循环执行时报错
25、 错误:java.io.FileNotFoundException,无法对已映射用户区域的文件执行请求操作,具体所示。
26、 IO流未关闭导致问题。